This closes #3784 Co-authored-by: Leonard Xu <xbjtdcq@gmail.com> |
3 weeks ago | |
|---|---|---|
| .github | 4 weeks ago | |
| .idea | 11 months ago | |
| docs | 3 weeks ago | |
| flink-cdc-cli | 3 weeks ago | |
| flink-cdc-common | 3 weeks ago | |
| flink-cdc-composer | 3 weeks ago | |
| flink-cdc-connect | 3 weeks ago | |
| flink-cdc-dist | 1 month ago | |
| flink-cdc-e2e-tests | 3 weeks ago | |
| flink-cdc-migration-tests | 1 month ago | |
| flink-cdc-pipeline-model | 3 weeks ago | |
| flink-cdc-pipeline-udf-examples | 1 month ago | |
| flink-cdc-runtime | 3 weeks ago | |
| tools | 1 month ago | |
| .asf.yaml | 11 months ago | |
| .dlc.json | 2 months ago | |
| .gitignore | 1 year ago | |
| .gitmodules | 7 months ago | |
| Dockerfile | 6 months ago | |
| LICENSE | 11 months ago | |
| NOTICE | 2 months ago | |
| README.md | 1 month ago | |
| pom.xml | 1 month ago | |
README.md
![]()




Flink CDC is a distributed data integration tool for real time data and batch data. Flink CDC brings the simplicity and elegance of data integration via YAML to describe the data movement and transformation in a Data Pipeline.
The Flink CDC prioritizes efficient end-to-end data integration and offers enhanced functionalities such as full database synchronization, sharding table synchronization, schema evolution and data transformation.
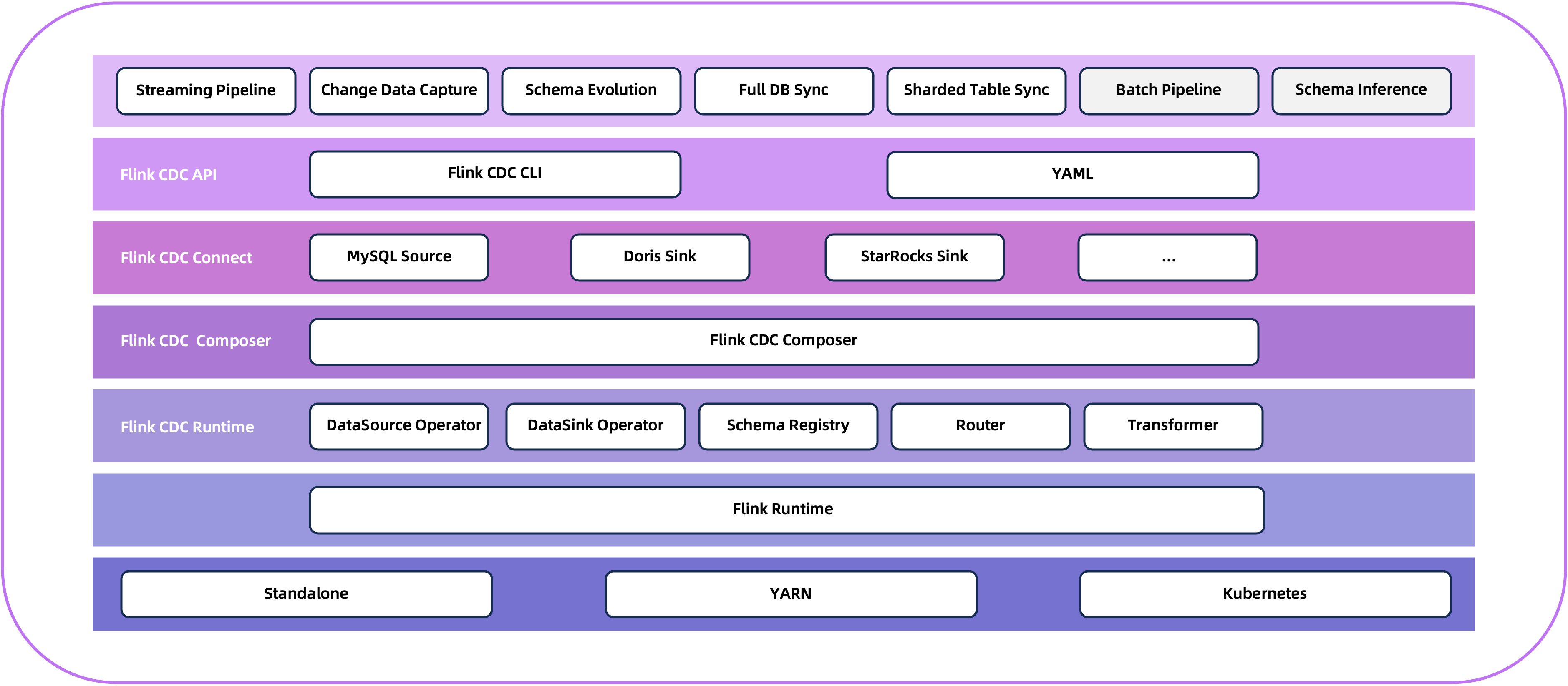
Getting Started
- Prepare a Apache Flink cluster and set up
FLINK_HOMEenvironment variable. - Download Flink CDC tar, unzip it and put jars of pipeline connector to Flink
libdirectory. - Create a YAML file to describe the data source and data sink, the following example synchronizes all tables under MySQL app_db database to Doris :
source:
type: mysql
hostname: localhost
port: 3306
username: root
password: 123456
tables: app_db.\.*
sink:
type: doris
fenodes: 127.0.0.1:8030
username: root
password: ""
transform:
- source-table: adb.web_order01
projection: \*, format('%S', product_name) as product_name
filter: addone(id) > 10 AND order_id > 100
description: project fields and filter
- source-table: adb.web_order02
projection: \*, format('%S', product_name) as product_name
filter: addone(id) > 20 AND order_id > 200
description: project fields and filter
route:
- source-table: app_db.orders
sink-table: ods_db.ods_orders
- source-table: app_db.shipments
sink-table: ods_db.ods_shipments
- source-table: app_db.products
sink-table: ods_db.ods_products
pipeline:
name: Sync MySQL Database to Doris
parallelism: 2
user-defined-function:
- name: addone
classpath: com.example.functions.AddOneFunctionClass
- name: format
classpath: com.example.functions.FormatFunctionClass
- Submit pipeline job using
flink-cdc.shscript.
bash bin/flink-cdc.sh /path/mysql-to-doris.yaml
- View job execution status through Flink WebUI or downstream database.
Try it out yourself with our more detailed tutorial. You can also see connector overview to view a comprehensive catalog of the connectors currently provided and understand more detailed configurations.
Join the Community
There are many ways to participate in the Apache Flink CDC community. The
mailing lists are the primary place where all Flink
committers are present. For user support and questions use the user mailing list. If you've found a problem of Flink CDC,
please create a Flink jira and tag it with the Flink CDC tag.
Bugs and feature requests can either be discussed on the dev mailing list or on Jira.
Contributing
Welcome to contribute to Flink CDC, please see our Developer Guide and APIs Guide.
License
Special Thanks
The Flink CDC community welcomes everyone who is willing to contribute, whether it's through submitting bug reports,
enhancing the documentation, or submitting code contributions for bug fixes, test additions, or new feature development.
Thanks to all contributors for their enthusiastic contributions.